■ HOME
AI字幕生成の「Whisper」導入が本当に簡単になった「Shotcut」2026
Whisper のアプリもFFmpeg も諸々のDLLも「Shotcut」に同梱されており
モデルをダウンロードするだけなので非常に簡単に導入できる。
面倒なコマンドは一切ない。GUIだけ
詳しくもない動画
AI字幕生成の「Whisper」導入「Shotcut」2026
--------------------------------------------------------------------
■Shotcut(フリー&オープンソース)
ダウンロード DL
https://www.shotcut.org/
https://www.shotcut.org/download/
Current Version: 26.2.26 [2026-04-07]での最新
Show downloads for GNU/Linux | macOS | Microsoft Windows | All
(例)
Windows 10/11 on Intel or AMD CPU
Windows installer Windows portable zip
適宜OSに合わせてDLする。
exeインストールか、ZIP展開して起動。
■「Shotcut」初期の頃と比べて本当に進化した。
各ウィンドウの配置や大きさも自由に変えられる。
右上のボタンでBlenderのように作業別にレイアウトが一発で変更できる。
機能は多すぎて紹介しきれない。
入力は可変レートであれば自動で変換かつ任意で保存(そのままも可)。
出力は多くのプリセットがあり、そのまま出力してもいいが、更に細かい設定もできる。
・4K、8Kに対応
・映像・音声:FFmpeg
によりほとんどの動画フォーマットに対応
・画像:AVIF、BMP、GIF、JPEG、PNG、SVG。TIFF、WebP。
・字幕:SRT、VTT、ASS、SSA
・Lottie、rawr、Rive、After Effects
・多彩なフィルター、エフェクト
・マルチフォーマットタイムラインで解像度とフレームレートを自由に組める
・他多数
簡単な編集作業ならこれだけで十分だと思う。
昔からFFmpeg はバージョンによって仕様が変わるので気を付けなければならないが
同梱されているFFmpegを最新のものが良いからと変更しないように注意したい。
(pythonベースのアプリと同じ)
■字幕とテキスト
普通にリッチテキスト作成可能。出力はできないが
ソフト字幕は作成可能でインポート(.srt .vtt .ass .ssa)&エクスポート(.srt)可能。
<Whisper による字幕生成>
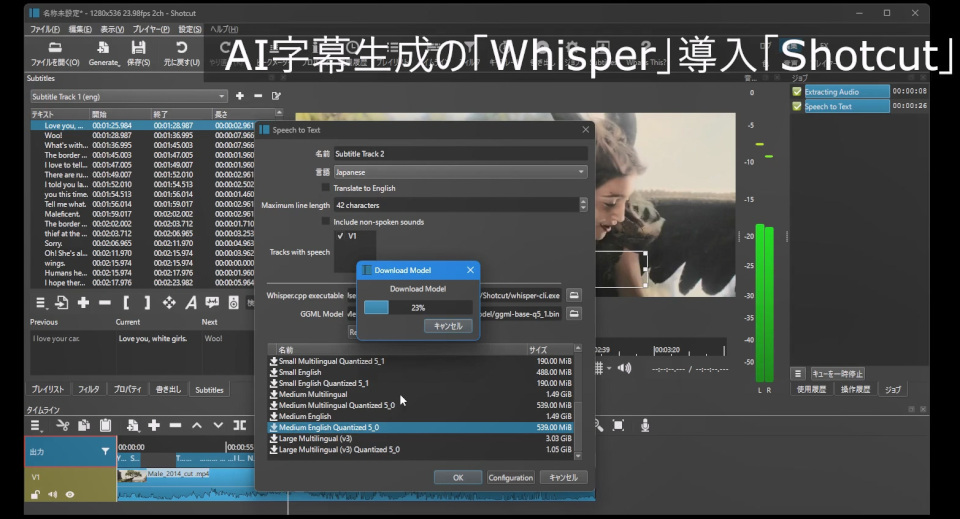
■ 動画を入れて「音声から字幕」
1. 動画または音声をタイムラインに入れておく(D&DでもプレイリストからでもOK)
2.「Subtitles」のタブをクリック(デフォルト位置で左中央)
(表示されてなければメニュー >表示 >Subtitles)
「Subtitles」ウィンドウの下方にボタンアイコンがある(英語名だが)
「=(ポップアップメニュー)」「インポート」「+」「-」...「A」「音声から字幕」「字幕から音声」「検索」
(字幕から音声も凄いな。。。やってないけど)
3.「音声から字幕」をクリック(フキダシに波形の入ったアイコン)
>「Speech to Text」ウィンドウ
■「Speech to Text」ウィンドウ
(例)
1. 動画の「言語」を選択「English」
2. 字幕にするトラックにチェックを入れる(他は外す)「V2」
3.「Configuration」ボタン
ダウンロードできるモデルの一覧から
「Base English Quantized 5_1」をクリックすると「DLするか?」のダイアログがでるので
「OK」でDLされチェックマークが付く(モデル ggml-base.en-q5_1.bin)。
4. そのまま選択した状態(モデル選択)で「OK」ボタン
字幕生成が始まり右にタスクの状態が表示される。
(マルチタスクなので他の作業をしていてもOK)
■ 字幕をタイムラインに出力(焼き付け)
1. 完了すると「Subtitles」ウィンドウに新しいトラックが追加されているので
上のポップアップから字幕を選択し
「A」のボタンでタイムラインに出力する(焼き付け用)。
2.「フィルタ」タブの出力設定で
(複数あって同じ名前「Subtitle Burn In」だが、選択すると下の字幕トラック名は変わる)
一番下にチェックが入っているか確認(新しい)。
選択すると画面上で位置を移動できる。フォント、輪郭、色など各種設定もある程度できる。
チェックをなくすと消える(焼き付けなし)。
モデルをDLしたデフォルトのディレクトリ
C:\Users\username\AppData\Local\Meltytech\Shotcut\extensions\whispermodel
(「AppData」フォルダは隠しフォルダになってるのでフォルダオプションで表示)
日本語の場合「言語」を選択「Japanese」
モデルを「Multilingual」のバージョンにする。
英語は軽量モデルでも精度は高いが他は怪しいので
最低 Medium か Large あたりでないと精度は望めないかもしれない(試してない)
q の付くQuantized バージョンは
精度が若干落ちるが高速で負荷の少ないモデル。
PCスペックのある人は精度の高いモデルの方がいいに決まってる。
--------------------------------------------------------------------
モデルの最新のものはここからDLする
https://huggingface.co/ggerganov/whisper.cpp/tree/main
前述のggml-base.en-q5_1.bin は2年前
ggml-base.en-q8_0.bin は1年前でやってみたところ精度がよい。
なのでDLして、デフォルトのディレクトリ先に移動させる(任意でもOK)。
日本語ならモデルは重いが v3-turbo あたりがいいかもしれない
v3-turbo-q8 は2分くらいで終了しまった
「Speech to Text」ウィンドウの「GGML Model」の右アイコンから
ファイル参照「ggml-base.en-q8_0.bin」を開く。
リストには入ってこないので、選択されてない状態で「OK」ボタン。
後は同じ。。。
字幕に「♪♪」が入ってる場合がある(ま。確かにBGMありますけど。。。)
SRT字幕で保存してメモ帳で「♪♪」を「空白」にして「全て置換」で消す
SubtitleWorkshop 6.0e-8 に入れて保存すれば綺麗に消える。
crayonzen [2026-04-07]
--------------------------------------------------------------------